# Database
이번 주제는 데이터베이스(Database)에 관련된 내용입니다. 항상 말하지만 이 블로그는 평범하지 않기 때문에(?) 기존의 전통적인 방식으로 디비에 대해서 공부했던 분들은 이번 포스팅을 보면 기존 가치관(?)이 흔들릴 수 있으니 미리 알려드립니다. 처음 디비를 공부하는 사람들은 차후 레퍼런스를 볼때 아래 개념들을 참고하여 생각을 해보시면 좋을 것 같습니다.
디비에서 SQL 주제 하나만 가지고도 300 페이지 짜리 포스팅 작성이 가능합니다. 그만큼 디비에 관련해 공부해야 할 양이 방대합니다. 예전에는 DBA(Database Administrator)라고 해서 디비만 전문으로 하는 사람이 있을 정도로 디비 하나만 떼어놓고 보아도 아주 큰 분야입니다. 요즘은 백엔드 개발자가 디비도 하고 프론트엔드까지 하면서 풀스택이 되고 데브옵스(DevOps)까지 해서 인프라까지 다 하니깐 필수적으로 알아야하는 사항입니다.(이놈의 직업은 치매는 안걸린다고 합니다.) 어쨌든 필수적인 개념 위주로 짧게 설명하도록 최대한 노력해보겠습니다.
고전적인 디비의 개념들이 틀린 것이 아닌데 요즘 기술 발전이 하도 빠르다보니까 구기술과 신기술이 섞이면서 헷갈릴 수 있게 된 것 같습니다. 오래된 시니어들이야 해당 풍파(?)를 다 겪었기 때문에 이상할 것이 없을 수도 있지만, 새로 개발을 시작하는 분들은 기존에 오래된 책들이나 전통적인 개념으로 요즘 나오는 기술을 보면 매우 헷갈릴 수도 있을 것 같습니다.
다음은 고전적인 잘못된 일반 상식들입니다.
- 디비는 크게 SQL과 NoSQL로 나뉘어져 있다.
- SQL은 Schema가 존재하고 NoSQL은 Schemaless이다.
- SQL은 관계형 데이터베이스(Relational Database)이고 NoSQL은 비관계형이다.
- NoSQL은 트렌젝션(Transaction)과 트리거(Trigger)를 지원하지 않는다.
# 디비 주요 개념
고전적인 디비 개념을 다음과 같이 정의하는 경우가 많습니다.
SQL DB는 정형화된 데이터를 저장하는 스키마가 있고 관계형 데이터베이스이며 ACID 특성을 따르고 MSSQL, MySQL, MariaDB, PostgreSql등이 있다.
NoSQL은 Json 형태의 비정형 데이터를 저장하고 스키마가 없으며 관계를 가지지 아니하고 CAP 이론을 따르며 MongoDB, DynamoDB등이 있다.
이는 무슨 디비는 뭐다라는 식으로 정해서 생각해서 이해하다보니 그런 것 같습니다. 각 주제 별로 아래 자세히 설명합니다.
# SQL vs NoSQL
SQL은 Structured Query Language의 약자로 디비가 아니고 언어입니다. NoSQL은 SQL이 아닌 것들을 한 번에 부르려니깐 적당한 단어가 없어서 그냥 No + SQL이라고 한 것입니다. SQL의 반대 개념이 아니고 그냥 "SQL이 아닌 것들"에 더 가깝습니다.(이것은 소설이 아니고 팩트입니다.)
보통 MSSQL, MySQL는 SQL, MongoDB는 NoSQL 공식처럼 외우는데, 어떤 디비가 SQL이고 NoSQL인 것이 아니고 해당 디비가 SQL을 지원하느냐에 따라서 SQL DB인지 아닌지를 구분하게 됩니다. 만약에 MongoDB가 SQL을 지원하면 MongoDB가 SQL DB가 되는 것입니다. 요즘은 NoSQL DB에 추상화된 레이어를 올려서 SQL 언어로 질의를 할 수 있게 하는 오픈소스 프로젝트가 많이 나와 있습니다. 디비와 언어의 개념을 분리하여 생각하여야 합니다.
# Schema
다음은 일반적인 SQL DB Schema입니다.
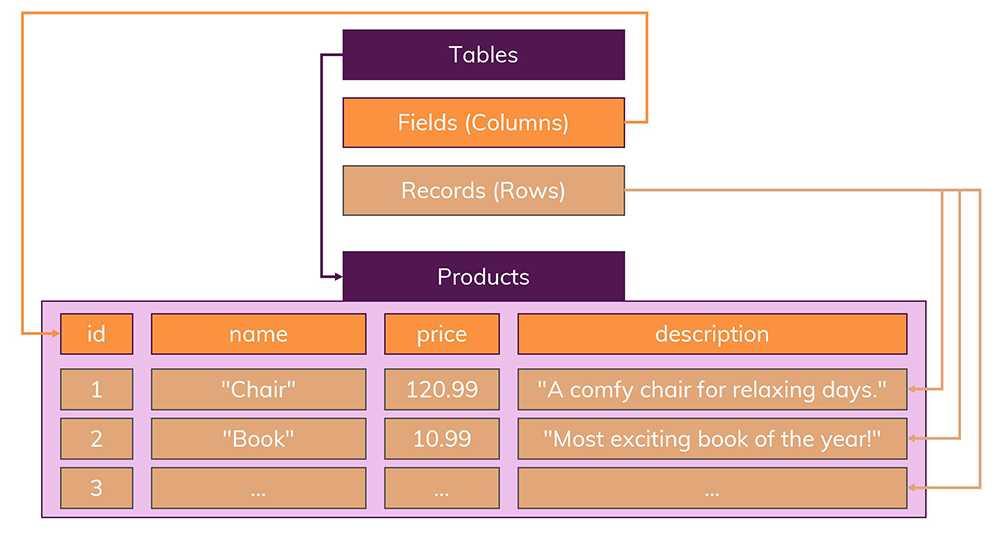 출처: academind
출처: academind
다음은 NoSQL DB의 Schema 없는 형태의 저장 형식입니다.
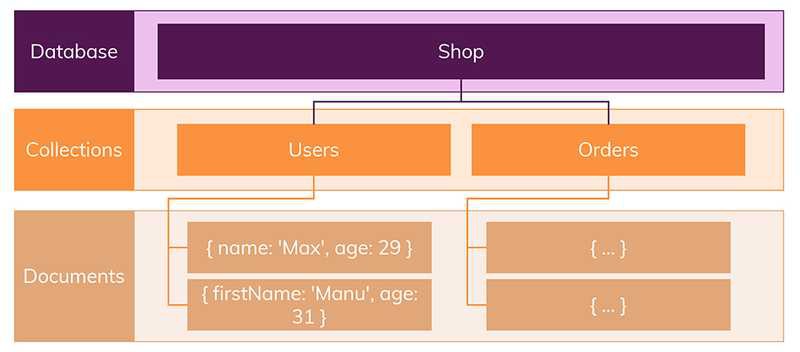 출처: academind
출처: academind
두 가지 관점에서 생각해봐야 합니다.
첫째, SQL DB에서는 꼭 스키마를 정하고 해당 스키마에만 맞게 데이터를 저장하고 읽고 쓴다고 알고 있는데, 스키마라는 것은 SQL을 사용하기 위하여 따라오는 필연적인 도구일 뿐이지 그 자체가 SQL DB를 지정하는 바는 아닙니다. 실례로, AWS의 Athena의 경우 NoSQL DB의 특성인 Json 기반으로 비정형 데이터를 저장하고 그 위에 스키마를 정의하여 SQL을 사용할 수 있게 되어 있습니다. NoSQL의 특성인 비정형데이터를 저장하고 SQL로 질의를 하면 이 데이터베이스는 SQL DB인가요? NoSQL DB인가요?
둘째, NoSQL DB에서는 스키마를 가지지 않는다라고 많이 얘기하는데, 실제로 실무를 할 때는 스키마를 가지게 됩니다. 요즘 많이 사용하는 TypeScript, ORM(Object-relatinal mapping), GraphQL등 기술들을 사용하면 자연적으로 스키마가 정해지게 됩니다.(협업을 하면서 스키마가 없다고 정말 스키마 없이 작업하는 경우는 없다고 보아도 됩니다.) NoSQL이 스키마가 없다라는 것이 틀린 표현이 아니지만 스키마가 유연하다가 더 올바른 표현 같습니다. 실례로, NoSQL 기반의 DynamoDB를 AppSync와 같이 사용할 때는 엄격한 스키마를 가지게 됩니다. 스키마 없이 읽고 쓰는 것 자체가 불가합니다. 비정형으로 데이터 형식으로 저장하지만 완벽하게 스키마를 통해서 접근한다면 이는 NoSQL인가요? SQL인가요?
Schema라는 것이 꼭 SQL을 결정짓는 요소도 아니고, NoSQL이라고 Schema를 안쓰는 것도 아니라는 얘기입니다. Schema는 DB의 형태가 아닌 단순히 어떤 형태로 데이터를 읽고 쓰느냐의 관점으로 봐야 합니다.
# Relations
다음은 일반적인 SQL DB의 관계형 데이터베이스의 구조입니다.
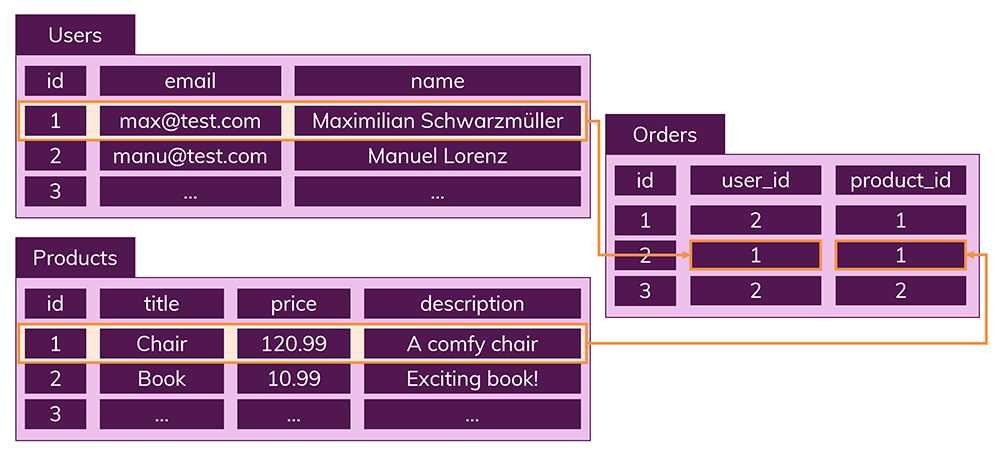 출처: academind
출처: academind
다음은 NoSQL DB의 비관계형 저장 형식입니다.
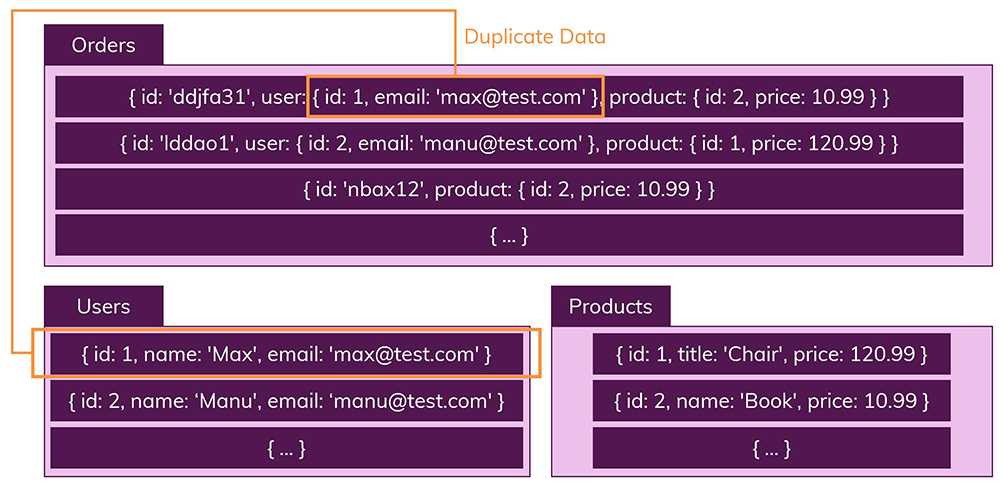 출처: academind
출처: academind
보통 SQL DB는 데이터를 중복하지 아니하고 관계를 가지고 일관성을 유지하고, NoSQL은 관계를 가지지 않기 때문에 데이터를 중복으로 저장한다고 합니다.
일반적으로 DB를 사용하는 이유가 일관성을 지키기 위함인데, "데이터를 중복하라고?" 처음 NoSQL의 이런 설명을 보고 어이가 없었습니다. 실제로 중복을 활용한 좋은 트릭들이 있고 실무에서도 사용되긴 하지만 실제로 "중복"이라는 것은 데이터 관점에서 그다지 좋은 내용은 아닙니다. 중복의 제일 문제는 원본 데이터가 바뀐 경우 중복 데이터를 다 찾아서 바꿔줘야 한다는 것입니다. 가뜩이나 Massive Update가 힘든 NoSQL에서 데이터 중복을 수정하려고 하면 엄청난 코스트를 불러옵니다.
AWS re:invent를 쭉 지켜오신 분들은 아시겠지만, 처음 NoSQL 기반의 DynamoDB가 나왔을 때 빠른 속도를 앞세워 중복을 하더라도 하나의 디비에 모든 것을 저장하는 방식이었습니다. (차후 나름 중복하지 않고 관계를 가지는 다양한 아키텍처들을 소개하였습니다.) 최근 re:invent에서는 다 쪼개라고 합니다. AWS의 AppSync 내용을 보시면 SQL DB와 다름이 없습니다. DynamoDB 하나하나가 테이블의 역할을 가지고 키를 가지고 관계를 형성하고 중복을 허용하지 않는 구조입니다.(기술 발전에 따라 기술 설명이 달라지는 것은 당연한 것으로 비방의 의도는 전혀 없습니다.)
관계(Relations) 또한 SQL, NoSQL을 결정짓는 요소가 아닙니다. 데이터의 일관성을 유지하고 중복을 피하기 위해서라도 NoSQL에서 관계는 필요하고 그런 구조로 작성을 해야 합니다.(NoSQL의 중복을 이용한 트릭은 여전히 유효하며 성능을 위해서도 적절한 곳에 적극 활용해야 합니다.)
# Transaction & Trigger
불과 몇 년 전에 이 포스팅을 작성했으면 아니라고 할 뻔한(?) 내용입니다. 일반적인 NoSQL DB의 내부 아키텍처 특성상 Massive Update, Transaction, Trigger를 구현하기가 까다롭습니다. 그럼에도 불구하고 지금은 서비스 차원에서 해당 기능을 제공합니다. DynamoDB, Firestore등 예전에는 지원하지 않았거나 미약했던 Transaction, Trigger 기능을 모두 지원하고 지금은 CAP뿐만 아니라 ACID 특성도 가질 수 있게 되었습니다. 이는 설계상에 변화를 가져올 수 있기 때문에 이런 트렌드는 잘 눈여겨봐야 합니다. 그만큼 기술 발전이 빠릅니다.
# Big Data
빅데이터란 단순히 SQL, NoSQL 등의 특성이 아닌 데이터 웨어하우스, 데이터 레이크등의 개념과 함께 아키텍처의 개념으로 보아야 합니다. 관련된 기술은 Hadoop, RedShift, BigQuery, Athena등이 있습니다.(빅데이터 주제 하나만 해도 수백 페이지짜리 포스팅이라 차후 다시 정리하겠습니다. ㅠㅠ)
# 어떤 디비를 사용해야 하는가?
엄연하게 자사의 기준(사실 내 기준)이지만 실무에서 디비를 나누는 기준에 대해서 몇 가지 설명드리려고 합니다.
# 스타트업이냐? 아니냐?
정확하게 얘기하면 구현하려는 "서비스/프로젝트가 불확실성이 크냐? 적냐?" 입니다. 스타트업 같이 불확실성이 큰 경우, 비즈니스 로직의 변화가 커서 빠른 변화를 대응하기에는 SQL 계열 보다는 NoSQL 형태가 좋습니다. 꼭 전체 서비스로만 볼 것이 아니고 마이크로서비스의 경우 일관적이고 전형적인 데이터 구조에서는 SQL이 유리하며, 변화무쌍(?)한 데이터 구조가 예상된다면 NoSQL을 섞어서 사용하는 것이 좋습니다.
# 개별 데이터 관점 vs 통계 관점
개별 데이터 관점에서 데이터를 읽고 쓰기에는 NoSQL 계열이 좋지만, 통계적 관점에서는 SQL 계열이 좋습니다. NoSQL 계열이 안되는 건 아니지만 통계적 처리를 하기가 조금 까다롭습니다. 주기적으로 통계를 내야 하는 내용은 SQL 디비를 이용하는 것이 좋습니다. 개별 데이터지만 주기적인 통계가 필요하다면 NoSQL 에서 트리거를 통해서 SQL 디비를 갱신해주고 통계는 SQL을 이용해서 뽑아 내는 하이브리드 방식도 추천합니다.
# 실시간이냐? 나중에 해도 되냐?
실시간 데이터 처리란 데이터를 데이터를 실시간 스트림 형태로 받아서 즉각적인 판단을 통해 처리함을 얘기합니다. 유저가 방금 검색한 검색어를 기반으로 그 페이지 하단에 관련된 광고를 띄워주거나, 쇼핑을 할 때 관심 있는 상품들을 클릭하면 연관성이 높은 상품을 오른쪽에 바로 추천해 주거나, 살지 말지 고민하고 있을 때 할인 쿠폰을 띄워주어 구매를 유도한다던지 다양한 용도로 활용되고 있습니다. 이런 기술을 구현하려면 로그를 그냥 쌓는 것이 아니고 로그 자체를 실시간 스트리밍으로 분석해야 하는데 이런 시스템을 구현하기에 AWS의 Kinesis가 최적화 되어 있습니다. 당장 도입을 하지 않더라도 R&D 할만한 내용이고 차후에 도입하기도 유연하니 알아두시면 좋을 것 같습니다.
나중에 해도 되는 것들은 우선적으로 로그를 쌓고 차후에 분석하는 방식으로 BigQuery나 Athena 같은 기술을 사용합니다.
# 데이터 주도 개발(Data Driven Development)
“A lot of times, people don't know what they want until you show it to them.” - Steve Jobs
“대부분의 경우 사람들은 그들에게 제품을 보여주기 전까지 그들이 무엇을 원하는지 모른다.” - 스티브잡스
제가 개인적으로 개발과 사업을 하면서 마음 속에 되뇌이는 문구입니다.
데이터 주도 개발(Data Driven Development)이란, 쉽게 설명하면 내가 만들고 싶은 것을 만드는 것이 아니고 사용자가 원하는 것을 만드는 것을 말합니다. 서비스를 만들면서 다양한 충분한 데이터를 쌓고 해당 데이터를 바탕으로 다음 내용을 기획하고 만들어 나가는 것입니다. 개발을 시작하는 분이라면 솔직히 SQL이고 NoSQL이고 이런 건 다 집어 던져도(?) 이 단락만큼은 기억을 했으면 하는 바람입니다. 특히 스타트업의 경우 비즈니스 관점에서 성공/실패를 가르는 요인이 될 수 있기 때문입니다. 회사의 존망(?)이 걸린 문제이니 개발자라고 개발적인 것만 알면 안되고 눈여겨 보았으면 합니다.
회사 대표나 기획자들의 자주하는 제일 큰 실수는 사용자가 무엇을 원하는지 알고 있다고 생각하는 것입니다. 사용자들 스스로도 무엇을 원하는지 모르는데, 기획자가 선견지명으로 그것을 안다면 그 분은 그냥 점집(?)을 하시면 될 것 같습니다. 특히나 불확실성이 높은 아이템일수록 알고 있다고 생각하는 것이 틀리거나 여러가지 외부 환경적인 요인에 의해 바뀔 가능성이 큽니다.
이런 불확실성 속에서도 비즈니스를 안정적으로 잘 이어나가려면 데이터를 중심으로 개발해야 합니다. 여기서 데이터란 주로 지표를 의미합니다. "지표는 거짓말을 하지 않는다" 이런 말이 있습니다. 지표를 심고 측정하고 판단하고 그 판단을 기준으로 다음 기획을 하고 다시 지표 심고 측정하고를 반복으로 개발하는 것을 데이터 드리븐 개발이라고 합니다. 심하게 표현하면 개발 시간보다 지표 심고 판단하는데 시간을 더 할애해도 될 만큼 중요합니다. 주관적인 상황에서 객관성을 유지시켜 줍니다.
이미 게임 산업에는 데이터 애널리스트(Data Analyst, 또는 Data Scientist)가 프로젝트 별로 붙어서 개발하는 곳도 많습니다. 데이터 분석에 따라 매출이 수십에서 수백 배 차이가 나는 것을 직접 경험했습니다. 전문 애널리스트가 있으면 좋지만 요즘 풀스택 개발자들이 앞뒤(?) 다 하듯이 기획자들도 기획과 함께 데이터 주도적으로 개발하는 곳이 많으며 기획과 데이터를 하나의 흐름으로 묶어서 생각하기 때문에 효율도 좋고 성공 확률도 늘어납니다. 요즘은 기획자가 광고를 직접 집행하고 CPI, ARPU, LTV등을 계산하지 못하면 안 뽑는 회사도 늘어나는 추세입니다. 마케팅은 뭐하고 기획자가 그걸 왜해?(형이 거기서 왜나와?) 할 수 있는데, 마케팅팀이 데이터를 보고 기획자에게 전달하고 다시 같이 기획하고 하면서 커뮤니케이션의 로스도 심하고 전체적인 흐름을 보고 바로 상황에 맞는 기획을 구현하고 대응해 나가는 것이 훨씬 효율적입니다.
디비를 무엇을 사용하느냐보다 회사가 데이터 드리븐 개발을 할 수 있도록 개발자와 기획이 협업이 잘 되는 것이 매우 중요합니다.
# 정리
다음과 같은 상황에서 다음과 같은 디비를 주로 활용합니다.
# 일반적인 상황
불확실성과 유연한 대응을 전제로 NoSQL 계열 디비를 사용합니다.
# 주기적인 실시간 통계가 필요한 상황
통계용 NoSQL 디비를 구축하거나 SQL 디비를 하이브리드로 사용합니다.
# 빅데이터 통계가 필요한 상황
비용에 효율적인 BigQuery를 사용합니다. 데이터 드리븐 방식으로 개발할 경우, 일 로깅 데이터가 수십 기가도 나올 수가 있습니다. 이는 구현에 따라 로깅&분석 비용만 매달 수백, 수천 만원이 나올 수도 있습니다. Google Analytics의 경우 저장 비용은 무료이고 BigQuery를 활용한 쿼리 비용만 지불합니다. Athena의 경우 쿼리 비용만 지불하는 것은 동일하나 로깅을 스택하는 비용과 저장 비용을 별도로 내야 합니다. 빅데이터 처리 기술인 Hadoop과 RedShift도 스타트업이 초반에 감당하기에는 너무 큰 비용이 들어갑니다.(일부에 활용하기는 좋습니다.)
# 실시간 대응이 필요한 상황
Kinesis Firehose + Lambda 조합을 통하여 스트리밍 로그를 분석하고 대응합니다.
# 기타
풀 텍스트 검색(Elastic Search), 캐싱(Redis)등 상황에 맞는 추가적인 디비를 활용하고 해당 내용은 차후 상세 아키텍처에 하나씩 기술되어 있습니다.
← Serverless API →